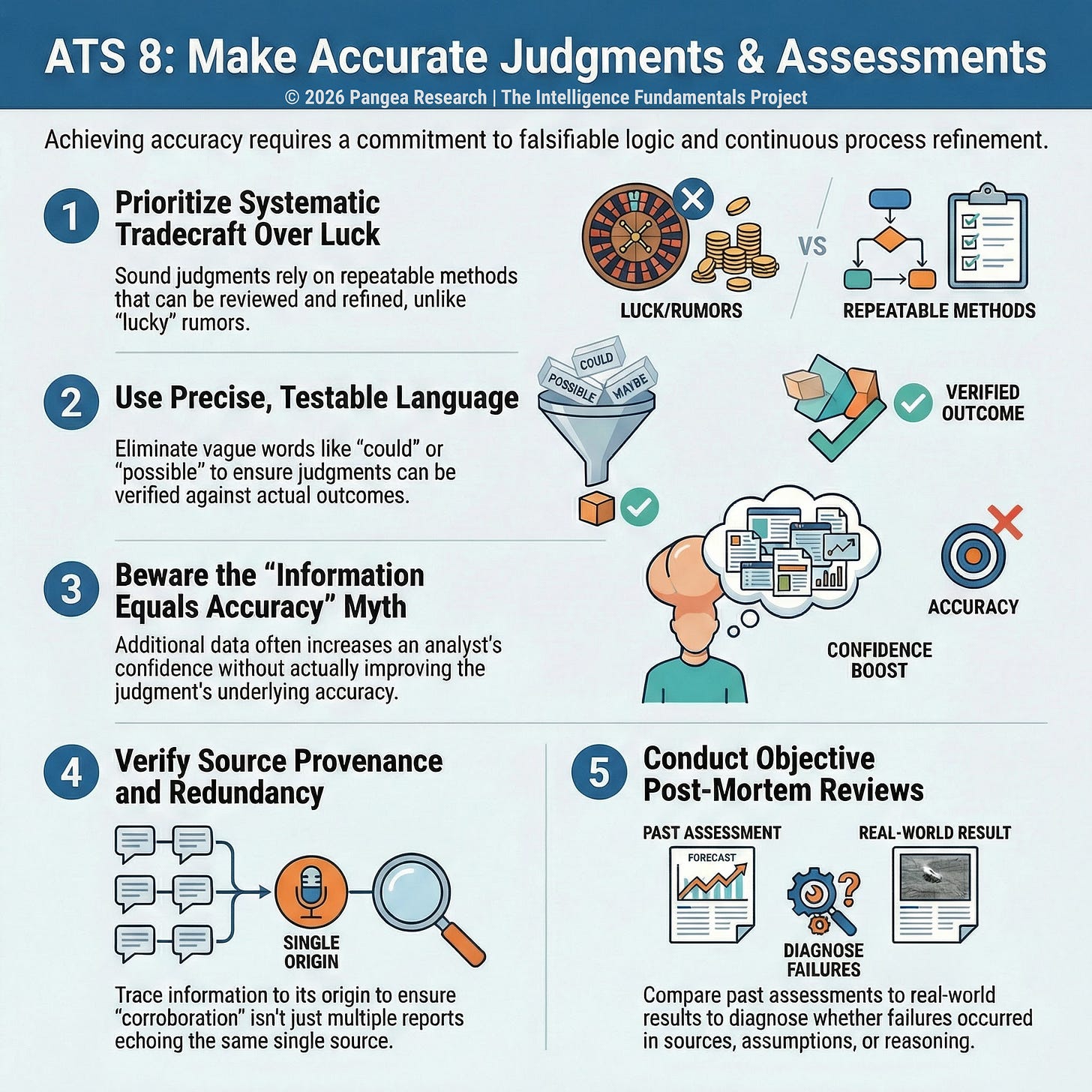
Analytic Tradecraft Standard 8 requires that intelligence products “apply expertise and logic to make the most accurate judgments and assessments possible, based on the information available and known information gaps” (ICD 203 2015). Every analyst already wants to be right; nobody sits down to write an assessment hoping to get it wrong. But the standard requires that accuracy be built into the process, evaluated after the fact, and understood as a product of how analysts think, write, and handle feedback.
Joint doctrine treats accuracy as an attribute of intelligence excellence: intelligence must be factually correct, relay the situation as it actually exists, and provide an understanding of the operational environment based on the rational judgment of available information (JP 2-0 2013). Army doctrine adds that intelligence should accurately identify threat intentions, capabilities, limitations, composition, and dispositions, and should be derived from multiple sources and disciplines to minimize the possibility of deception or misinterpretation (FM 2-0 2023). Both formulations define accuracy relative to the information available at the time, which means an analyst who reaches the best-supported conclusion from the evidence in hand has met the standard even if later information reveals a different picture. An analyst who reaches the right conclusion through sloppy reasoning or lucky guessing hasn’t, because the process that produced the answer won’t reliably produce correct answers the next time.
A corporate intelligence analyst who correctly predicts a competitor’s market entry because they happened to overhear a rumor at a conference got lucky. An analyst who systematically evaluated the competitor’s patent filings, hiring patterns, and supplier relationships and concluded a market entry was likely within eighteen months has demonstrated sound tradecraft, even if the entry happens at twenty-four months instead. The rumor-based prediction can’t be repeated or reviewed for process quality, and it offers no guidance for the next assessment on a different competitor. The systematic approach can be repeated, its logic can be examined when the prediction misses, and its methods can be refined based on what the miss reveals. Accuracy as a tradecraft standard lives in that distinction between a judgment you can learn from and one you can’t.
Clarity
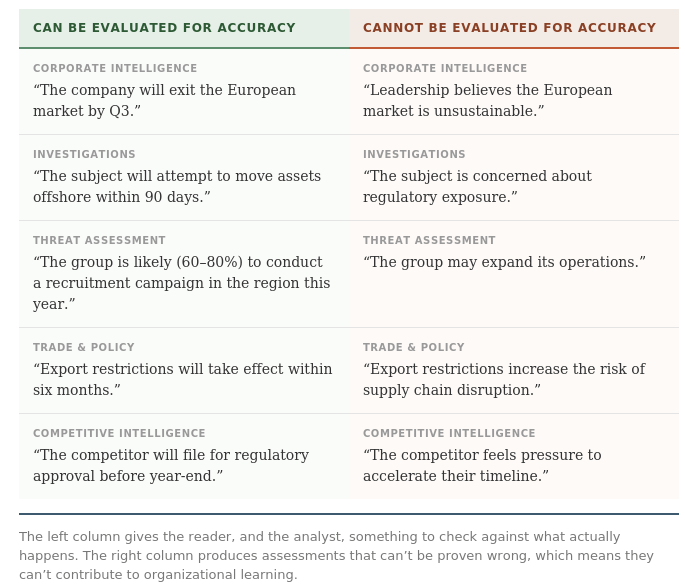
ICD203 ties accuracy directly to clarity: “the analytic message a customer receives should be the one the analyst intended to send” (ICD 203 2015). Products should express judgments as clearly and precisely as possible, reducing ambiguity by addressing the likelihood, timing, and nature of the outcome or development, because clarity of meaning permits assessment for accuracy when all necessary information is available (ICD 203 2015). An assessment that can be read two different ways can’t be evaluated for accuracy, because there’s no way to determine after the fact whether the analyst was right or wrong. If a threat assessment states that an attack “could occur in the coming months,” the analyst can claim credit regardless of outcome: if the attack happens, the assessment warned of it; if it doesn’t, “could” never committed to a probability. The assessment was unfalsifiable from the moment it was written.
Vague probability language like “possible,” “may,” and “could” makes this problem worse. An analyst who writes “it is possible the suspect has relocated” has produced a sentence that is technically true about anyone, anywhere, at any time. It communicates nothing a reader can evaluate, and it shields the analyst from ever being held accountable for a specific call. ICD203 also requires that products present all judgments that would be useful to customers, and should not avoid difficult judgments in order to minimize the risk of being wrong (ICD 203 2015). An analyst who replaces every specific prediction with “it remains unclear” or “several outcomes are possible” has eliminated the risk of being provably wrong, but they’ve also eliminated the value of the analysis.
DIA requires analysts to make judgments only on outcomes, actions, or behavior, and generally prohibits assessments on a foreign actor’s mental states or beliefs because they are inherently untestable and difficult to evaluate without specialized expertise (Kwoun & Schmor 2021). DIA also prohibits relative assessments like “increases the risk of” (Kwoun & Schmor 2021). “The government will restrict exports within six months” is testable. “The government believes export restrictions are necessary” is not, because the analyst has no reliable way to know what the government believes and no way to verify the assessment after the fact. Any analyst working outside the IC can apply the same discipline: before writing a judgment, ask whether you’ll be able to tell, six months from now, whether you were right. If the answer is no, the judgment needs to be rewritten or acknowledged as speculative.
Testable vs. Untestable Judgments
How Analysts Get It Wrong
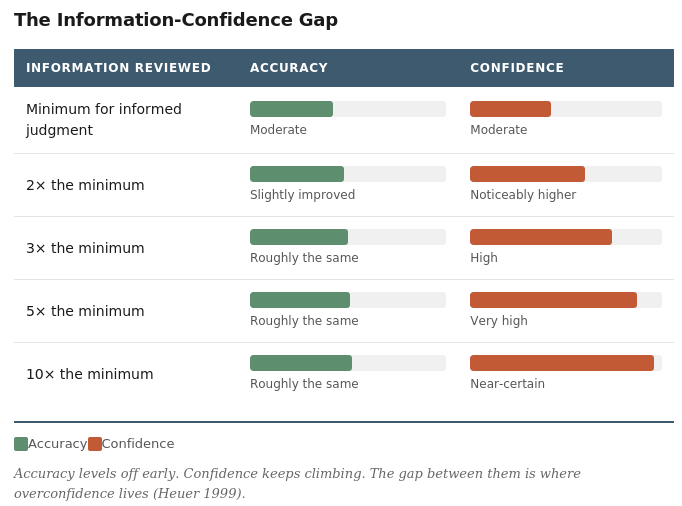
Once an experienced analyst has the minimum information necessary to make an informed judgment, obtaining additional information generally does not improve the accuracy of the estimate, but it does produce confidence (Heuer 1999). The analyst reads more reports, talks to more sources, and reviews more data, and each additional input makes them feel more certain about their judgment even though the judgment itself hasn't meaningfully improved. Heuer found this pattern consistently: additional information leads analysts to become more confident to the point of overconfidence (Heuer 1999). A law enforcement intelligence analyst preparing a threat assessment for a major public event might review fifty reports and feel substantially more certain than a colleague who reviewed fifteen, even if the additional thirty-five reports were redundant or drawn from the same underlying sources. The confidence grows with every additional report, but the accuracy of the underlying judgment stays roughly where it was after the first fifteen.
Experienced analysts have an imperfect understanding of what information they actually use in making judgments (Heuer 1999). They are unaware of the extent to which their judgments are determined by a few dominant factors rather than by the systematic integration of all available information (Heuer 1999). A due diligence analyst assessing a potential acquisition target might believe they’ve weighed financial disclosures, litigation history, regulatory filings, management backgrounds, and market positioning. Their actual judgment might rest almost entirely on two data points: a single red flag in the litigation history and a discrepancy in the financial statements. Everything else is cognitive furniture that makes the assessment feel comprehensive without actually contributing to the conclusion. When that judgment turns out to be wrong, the analyst will struggle to identify where the analysis failed because they don’t have an accurate picture of what drove it in the first place.
Five reports telling the same story feel more persuasive than three reports telling the same story, even when all five trace back to the same original source. Information may be consistent only because it is highly correlated or redundant (Heuer 1999). A law enforcement fusion center receiving multiple tips about a planned protest may treat each tip as independent corroboration, when all of them originate from the same social media post that was screenshotted and forwarded through different channels. The center’s confidence in the threat level is calibrated to the volume of reporting rather than to the actual breadth of independent evidence, and the gap between perceived corroboration and actual corroboration widens with each forwarded copy.
Analysts also tend to construct narratives of deliberate action when the actual cause was confusion, incompetence, or chance, because randomness, accident, and error are rejected as explanations for observed events (WMD Commission 2005). A private investigator tracking financial irregularities in a business will tend to build a narrative of deliberate malfeasance when the actual explanation might be disorganized recordkeeping and a bookkeeper who doesn’t understand the accounting software. The fraud narrative is more coherent, more satisfying as a story, and more likely to generate a clear recommendation to the client. It’s also wrong in a way that the investigation may never catch, because the evidence of disorganization looks a lot like evidence of concealment when you’re already looking for fraud.
Incremental Erosion
Information arrives one piece at a time, and that incremental flow systematically degrades accuracy. Each individual report gets compared against whatever the analyst currently thinks, and no single report is dramatic enough to change the picture, but the cumulative message carried by many pieces of information may be significant, and that significance is attenuated when the information is not examined as a whole (Heuer 1999). A corporate security director who receives a threat assessment in January and makes staffing decisions based on it is exposed if the threat environment shifted substantially over the following months but the analyst’s incremental approach never surfaced the change; the assessment was accurate when it was written, stopped being accurate gradually, and nobody flagged the transition.
A corporate intelligence analyst who has publicly briefed the executive team on a competitor’s strategy has staked a position, and commitment compounds the drift. Subsequent reporting that contradicts that position creates cognitive dissonance that the analyst resolves by reinterpreting the new information rather than revising the briefed conclusion (JP 2-0 2013). The analyst genuinely believes the contradictory information is less significant than it is, and the result is an increasingly inaccurate picture defended with increasing conviction. This dynamic plays out wherever analysts deliver assessments verbally or in high-visibility formats: a law enforcement intelligence analyst who briefed a threat at a command staff meeting will resist downgrading it in the next weekly report, because the revision feels like an admission of error rather than an honest response to changing information.
Source Verification
The accuracy of any judgment is bounded by the accuracy of the information it rests on. Joint doctrine requires comparing past data received from a source with ground truth, meaning subsequent events or information that confirm or contradict the source’s previous reporting, to evaluate how much weight new information from that source deserves (JP 2-0 2013). An analyst who tracks which sources have proven reliable over time builds a calibrated sense of what their information base can support, while an analyst who treats all sources as roughly equivalent will produce judgments that reflect the average quality of their inputs, which means a single unreliable source can drag down an entire assessment.
The OSINT Handbook describes a benchmarking approach for open sources: compare information provided from a source with validated all-source intelligence, meaning assessments that draw on multiple intelligence disciplines and collection methods, to assess the likely accuracy of other information from that source (SACLANT 2002). A corporate intelligence analyst evaluating information from an industry publication can benchmark the publication’s past reporting against what actually happened. If the publication consistently reported a company’s earnings accurately but missed a major product failure, that tells the analyst something about the source’s strengths and limitations that should inform how much weight to place on its current reporting. First Draft’s verification guidance identifies provenance as the most important check in any verification process, because understanding where information originated reveals the context and motivation that determine how much the information can be trusted (Urbani 2019). An analyst who receives third-hand information about a competitor’s plans needs to trace that information back to its origin before building a judgment on it, because each intermediary introduces the possibility of distortion, editorialization, or simple misunderstanding.
The Intelligence Community’s experience with weapons of mass destruction assessments before the 2003 Iraq War illustrates what happens when source verification breaks down at scale. The IC relied too heavily on ambiguous imagery indicators, and analysts community-wide were unable to make fully informed judgments on the information they received, relying instead on nonspecific source lines to reach their assessments (WMD Commission 2005). The assessments appeared well-supported because multiple streams of reporting pointed in the same direction, but the underlying sources were thinner and more ambiguous than the finished products conveyed. Any analyst working with open sources faces a version of this problem: aggregator sites, industry reports, and news coverage may all appear to independently confirm a conclusion while drawing from the same original dataset or press release.
Evaluating Accuracy After the Fact
Looking back at what you got wrong is uncomfortable, and the biases that produced the original error also distort the evaluation. Analysts overestimate the quality of their analytical performance, and others underestimate the value and quality of their efforts (Heuer 1999). Once an outcome is known, people reconstruct their prior beliefs to align with what actually happened. An analyst who assessed a merger as unlikely and then watched the merger proceed will, in hindsight, recall their assessment as less confident than it actually was: “I always thought it was a close call.” An analyst who correctly predicted a market downturn will remember their prediction as more confident and more specific than it was: “I knew exactly what was coming.” These reconstructions happen unconsciously, and they make honest evaluation of past accuracy nearly impossible without written records of exactly what was assessed, at what confidence level, and what evidence supported it.
Retrospective evaluation should be standard procedure in fields where estimates are routinely updated at periodic intervals (Heuer 1999). A law enforcement fusion center that produces weekly threat assessments has a built-in opportunity to track accuracy over time: did last week’s assessment match what actually happened this week? A corporate intelligence shop that produces quarterly competitive assessments can review whether last quarter’s predictions about competitor behavior materialized. Heuer was explicit that the goal of learning from retrospective evaluation is achieved only if it is accomplished as part of an objective search for improved understanding, not to identify scapegoats or assess blame (Heuer 1999). Organizations that punish analysts for wrong predictions create incentives to hedge, avoid commitments, and write unfalsifiable assessments. Organizations that treat wrong predictions as diagnostic data, useful for identifying whether the failure was in the sources, the reasoning, or the assumptions, create incentives to commit clearly and revise the process where it actually broke.
ICD203 requires the heads of agencies and intelligence organizations within the IC to conduct internal programs of review and evaluation of finished intelligence products using the analytic standards as the core assessment criteria (ICD 203 2015). Most organizations outside the IC don’t have formal evaluation programs, but the underlying practice scales to any size. A private investigation firm could review a sample of completed cases each quarter, comparing the assessments delivered to clients against what subsequently came to light. A corporate intelligence team could track their competitive assessments against actual competitor behavior over the following year. The data for accuracy evaluation already exists in most organizations; what’s missing is the discipline of actually reviewing it.
A quarterly review doesn't need to be elaborate. Five questions, applied consistently to a sample of past assessments, will identify patterns over time:

The first two questions establish whether the assessment was right or wrong. The third identifies where the process broke. The fourth catches assessments that were written too vaguely to evaluate, which is itself a finding worth tracking. The fifth forces the analyst to connect the miss to a specific change in method rather than a general intention to do better.
Building Accuracy Into the Process
Analysis of competing hypotheses increases the odds of getting the right answer by requiring the analyst to evaluate evidence against multiple possibilities rather than building a case for one, and it leaves an audit trail showing the evidence used and how it was interpreted (Heuer 1999). The quality of information check requires analysts to evaluate how much confidence their judgments should carry based on the accuracy and reliability of the information base itself (CIA 2009). The precision of the language in the final product shapes whether accuracy can be measured at all. Burying verbs inside nouns weakens assessments: “chemical attacks are in violation of the treaty” obscures the claim, while “chemical attacks violate the treaty” states it directly (DIA 2015). Across a full assessment, nominalized verbs and passive constructions accumulate into language that sounds analytical but resists evaluation; if a reader can’t tell exactly what the analyst is claiming, neither can the analyst, and neither can anyone reviewing the product’s accuracy after the fact.
Heuer recommended inserting odds ratios or numerical probability ranges in parentheses to clarify key analytical points, arguing this should be standard practice (Heuer 1999). A sentence that reads “the group is likely (55 to 80 percent) to attempt an expansion into the adjacent territory within six months” can be evaluated after six months. A sentence that reads “the group may expand its operations” will never tell the analyst or anyone else whether the assessment was right. Army doctrine captures the integrity dimension underlying all of these techniques: the methodology, production, and use of intelligence should not be directed or manipulated to conform to a desired result, and integrity requires adherence to facts and truthfulness with which those facts are interpreted and presented (JP 2-0 2013). Accuracy rests on the analyst’s willingness to follow the evidence rather than the narrative, to commit to a judgment clearly enough that it can be proven wrong, and to look back honestly at whether it was; the techniques and frameworks exist to support that willingness, but they can’t replace it.
Closing
You’ll get some calls wrong, because intelligence operates on incomplete information about people and organizations that change their minds, make mistakes, and act unpredictably. Wrong calls that get reviewed, diagnosed for where the reasoning or the sources failed, and fed back into how you work are the ones that make the next assessment better. Wrong calls that disappear into the next tasking cycle without anyone checking are the ones that let the same failure repeat.
Write your judgments so they can be checked. Clear, specific language serves everyone involved: your readers know exactly what you’re telling them, you can trace a wrong call back to the source that misled you or the assumption that broke, and your organization builds pattern data from reviewed predictions that will reveal, over a few quarterly cycles, where the analytical process is strong and where it consistently breaks down.
References
Central Intelligence Agency. 2009. A Tradecraft Primer: Structured Analytic Techniques for Improving Intelligence Analysis. Washington, DC: Central Intelligence Agency.
Defense Intelligence Agency. 2015. Style Manual for Intelligence Production. Washington, DC: Defense Intelligence Agency.
Department of the Army. 2023. FM 2-0: Intelligence. Washington, DC: Department of the Army.
Urbani, Shaydanay. 2019. Verifying Online Information. First Draft.
Heuer, Richards J., Jr. 1999. Psychology of Intelligence Analysis. Washington, DC: Center for the Study of Intelligence, Central Intelligence Agency.
Joint Chiefs of Staff. 2013. Joint Publication 2-0: Joint Intelligence. Washington, DC: Joint Chiefs of Staff.
Kwoun, James S., and Robert W. Schmor. 2021. Analytic Tradecraft Standards: An Opportunity to Provide Decision Advantage for Army Commanders. Accessed December 3, 2025. https://www.armyupress.army.mil/Portals/7/military-review/Archives/English/MA-21/Kwoun-Tradecraft-Standards.pdf.
Office of the Director of National Intelligence. 2015. Intelligence Community Directive 203: Analytic Standards. Washington, DC: Office of the Director of National Intelligence.
SACLANT. 2002. Open Source Intelligence Handbook. Supreme Allied Commander Atlantic.
WMD Commission. 2005. Report of the Commission on the Intelligence Capabilities of the United States Regarding Weapons of Mass Destruction. Washington, DC.
This piece was first published on our Substack.
Read the original on Substack