Until ICS 206-01, the IC had no sourcing standard written specifically for open-source work. Intelligence Community Directive 203 sets analytic standards. ICD 206 sets sourcing requirements. Both apply to OSINT products, but neither tells analysts how to cite a social media post, document their use of an AI tool, or handle information that’s been aggregated and repackaged by a commercial data provider. Intelligence Community Standard 206-01 does. It is the only standard in the IC’s policy framework written specifically to address how Publicly Available Information (PAI), Commercially Available Information (CAI), and Open-Source Intelligence (OSINT) should be cited, described, and preserved in analytic products (ICS 206-01 2024).
The standard was originally issued in 2017 and substantially updated in December 2024. Between 2017 and 2024, the volume of PAI and CAI available to analysts grew enormously, AI tools became part of everyday collection and analytic workflows, and commercial data providers built entire businesses around aggregating, enriching, and reselling information from other sources. The 2024 revision responds to those changes by adding new and updated definitions for PAI, CAI, and OSINT terminology, and for the first time establishing citation requirements for artificial intelligence, including machine learning, computer vision, and generative AI (ICS 206-01 2024).
ICS 206-01 implements ICD 206, the IC’s sourcing directive covered in the previous article in this series. Where ICD 206 establishes general requirements for sourcing in finished intelligence, ICS 206-01 specifies how those requirements apply to information that comes from outside the classified collection apparatus: how to cite it, how to describe its quality, and how to preserve it when it might disappear. The standard also establishes the formal definitions the IC uses for PAI, CAI, and OSINT, giving these categories precise boundaries that most practitioners outside the IC have never seen written down. Those definitions are worth understanding even if you never work inside the IC, because they draw lines between information types that most of us use every day without distinguishing between them.
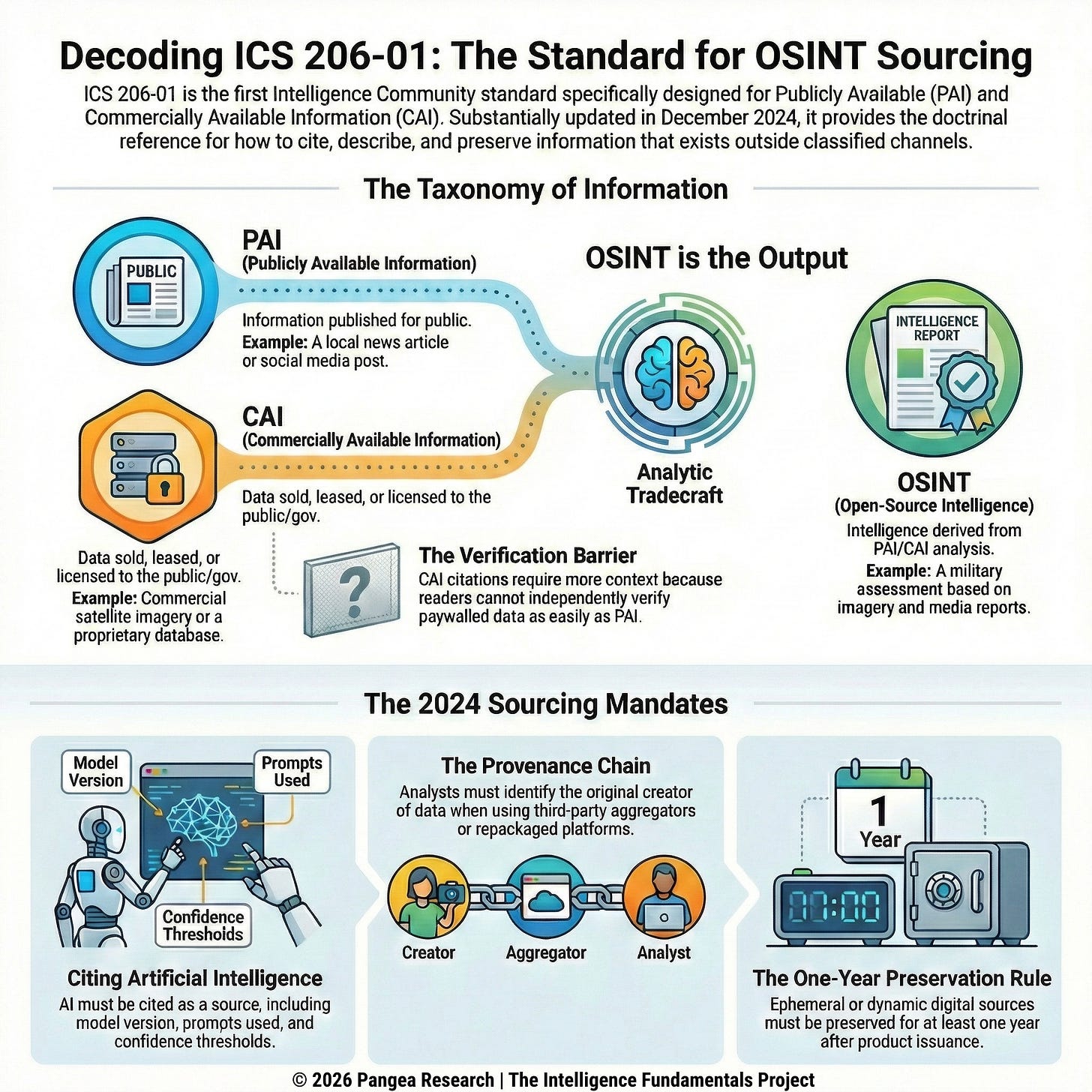
Three Categories of Information
The IC defines PAI, CAI, and OSINT as three separate categories, and the differences between them determine what an analyst owes the reader when citing each one. Each category describes a different relationship between the information, the public, and the analyst, and those differences affect how you evaluate the information, how you cite it, and what you owe the reader about its origins.
Publicly Available Information (PAI) is defined as “information that has been published or broadcast for public consumption, is available on request to the public, is accessible online or otherwise to the public, is available to the public by subscription or purchase, could be seen or heard by any casual observer, is made available at a meeting open to the public, or is obtained by visiting any place or attending any event that is open to the public” (ICS 206-01 2024).
Commercially Available Information (CAI) is defined as “any data or other information of a type customarily made available or obtainable and sold, leased, or licensed to members of the general public or to non-governmental entities for purposes other than governmental purposes.” CAI also includes data and information provided exclusively for government use that is “knowingly and voluntarily provided by, procured from, or made accessible by corporate entities at the request of a government entity or on their own initiative” (ICS 206-01 2024).
Open-Source Intelligence (OSINT) is defined as “intelligence derived exclusively from publicly or commercially available information that addresses specific intelligence priorities, requirements, or gaps” (ICS 206-01 2024). OSINT is what you get when PAI and CAI are collected, processed, and analyzed to answer an intelligence question. A news article is PAI. A commercial satellite image is CAI. An assessment of military force movements based on analysis of commercial satellite imagery and cross-referenced with media reporting is OSINT.
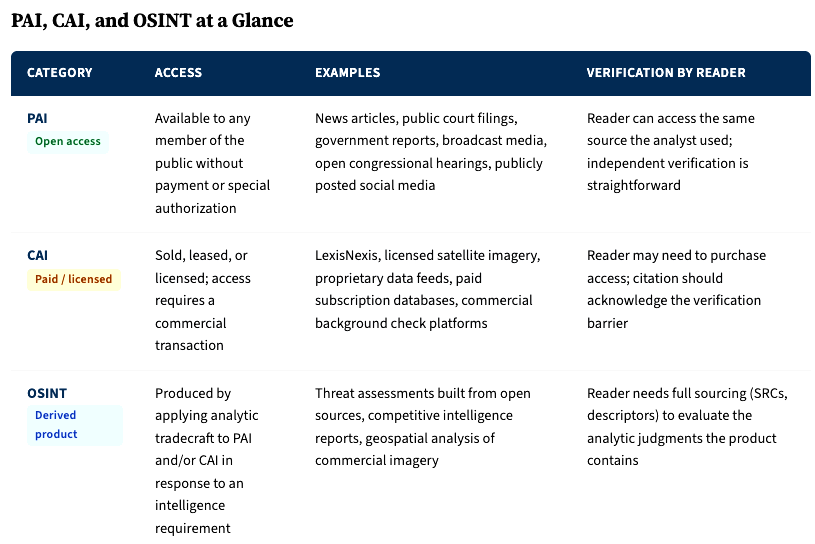
The PAI/CAI distinction matters for sourcing because it determines whether the reader can check your work. A reader who wants to verify a PAI source can go find the same publicly available information the analyst used. A reader who wants to verify a CAI source may need to purchase access to the same commercial platform, and that barrier to independent verification is something the citation should make visible. A corporate intelligence analyst citing a finding from a proprietary due diligence database owes the reader more context about that source than one citing a publicly available court filing, because the reader can pull up the court filing themselves but can’t access the database without a subscription.
The PAI/CAI versus OSINT distinction matters because it separates raw material from finished product. PAI and CAI are inputs. OSINT is what an analyst produces by applying tradecraft to those inputs in response to a defined intelligence question. A law enforcement analyst who pulls public social media posts about a person of interest has collected PAI. When that analyst integrates those posts with commercial data, public records, and their own assessment to produce a threat evaluation, they’ve produced OSINT. The sourcing requirements for the finished OSINT product are more demanding than those for passing along a piece of PAI, because the product contains analytic judgment and the reader needs to see what that judgment is built on.
Why the Categories Have Different Sourcing Obligations
ICS 206-01 sets different sourcing requirements depending on the type of product. A fully analyzed OSINT assessment requires the most complete sourcing: citations with quality descriptors that tell the reader how reliable each source is and how confident the analyst is in the information. A curated OSINT report (like a daily media summary) needs source identification so the reader knows where each item came from, but doesn’t require the same depth of quality description. Internal research holdings and reference databases need good metadata practices but don’t need formal citation architecture.

For practitioners outside the IC, these tiers map onto familiar work products. A corporate intelligence team’s competitive assessment is the equivalent of a stand-alone OSINT analytic product and should carry full sourcing. A daily media briefing compiled for executives is closer to a stand-alone OSINT product and needs source attribution. An internal research database sits below the line. Matching your sourcing effort to the type of product you’re delivering keeps the work proportional while making sure that the products carrying analytic judgment also carry the sourcing readers need to evaluate that judgment.
Citing AI
The 2017 version of ICS 206-01 didn’t mention artificial intelligence. By December 2024, AI tools had become common enough in collection, processing, and analysis that the IC added specific citation requirements for them (ICS 206-01 2024).
The standard defines AI broadly, consistent with federal statute: “a machine-based system that can, for a given set of human-defined objectives, make predictions, recommendations or decisions influencing real or virtual environments” (ICS 206-01 2024). That definition covers everything from a computer vision model identifying objects in satellite imagery to a generative AI system summarizing collected reporting.
ICS 206-01 requires analysts to cite AI tools with enough detail that a reader can evaluate what the tool contributed and how much to trust its output. The same model, with different training data, different settings, or a different prompt, can produce meaningfully different results. A generative AI system asked to summarize a collection of reports will produce different output depending on the model version, the prompt phrasing, and any system-level instructions. A computer vision model’s identification of objects in imagery depends on what it was trained on, its accuracy rate, and the confidence threshold the analyst applied. Without documenting these parameters, a reader has no way to evaluate or reproduce the result. The table below shows what those parameters are and how they should be cited.
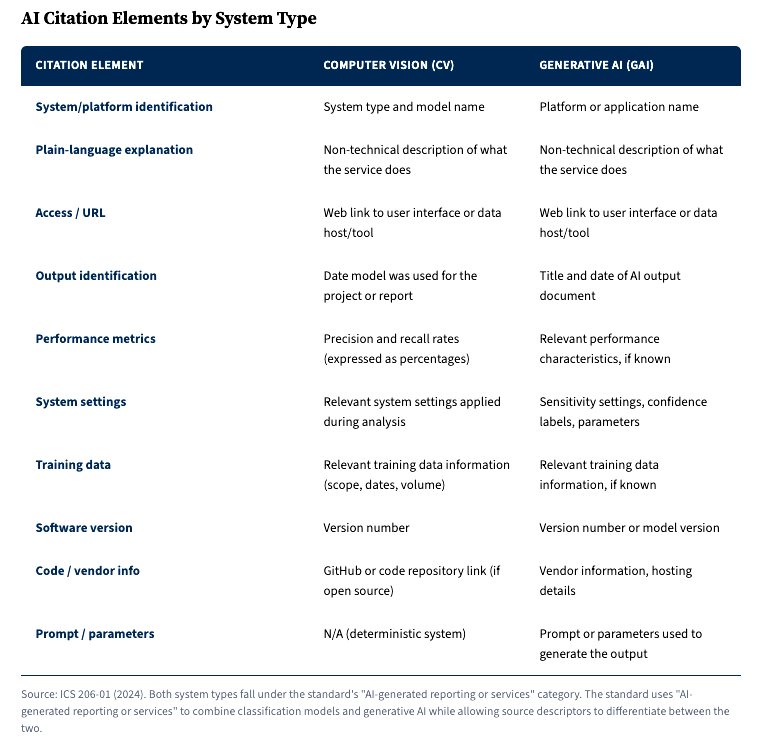
A corporate intelligence analyst who uses a generative AI tool to draft a preliminary summary of open-source reporting on a competitor’s supply chain, then incorporates elements of that summary into a finished assessment, owes the reader transparency about that process. A law enforcement analyst who uses a facial recognition system to identify a person of interest needs to document the system, its accuracy rate, the confidence score, and the comparison database used. A due diligence investigator who uses a commercial AI-powered screening platform to flag adverse media hits needs to note the platform, version, and any filtering parameters, because the same platform with different settings would produce different results.
ICS 206-01 treats AI tools as sources, and sources need to be cited with enough information for the reader to assess their reliability. An analyst wouldn’t cite a human source without noting the source’s access, reliability, and potential limitations. The same logic applies to AI. The model’s training data is its access: what information it can draw on. Its accuracy rate is its reliability metric. Its known failure modes and biases are its limitations. Documenting these in the citation lets the reader assess how much weight the AI-derived information can bear, the same way a source descriptor for a human source does.
Provenance Chains and Third-Party Data
When a PAI or CAI provider isn’t the original source of the data, ICS 206-01 requires the citation to say so. Third-party data providers aggregate, repackage, and redistribute data from other sources. A commercial platform might compile social media posts from multiple networks, enrich them with geolocation data and sentiment analysis, and present the result as a unified feed. The data the analyst sees has passed through multiple hands, and each handoff can strip context, introduce errors, or obscure where the information originally came from.
The standard specifies that when a provider is not the original source, the citation should include provenance details: who owns or created the original data, where it is hosted, and any enrichments or changes made to the original data (ICS 206-01 2024). This applies to social media, open-source press reporting, economic data, and anything else where the provider may have aggregated, resold, rehosted, or modified the original content.

A private investigator who runs a subject through a commercial background check platform is relying on data pulled from court records, credit bureaus, public filings, and other primary sources. The background check platform is a middleman, and its output reflects whatever data it has ingested, however it has processed that data, and whatever errors or gaps exist in its aggregation. Citing "AIPlatform.com" as the source without noting what underlying databases the platform draws from leaves the reader unable to assess whether the data is current, complete, or drawn from jurisdictions relevant to the investigation. A corporate intelligence analyst using a commercial geopolitical risk platform faces the same problem when the platform doesn't disclose its underlying sources: the citation should note what the platform draws from to the extent that's known, so the reader can judge how deep the foundation actually goes.
Source Preservation in the Digital Space
My ICD 206 article in this series covered the general requirement to preserve sources that are dynamic or ephemeral. ICS 206-01 sharpens that requirement for PAI and CAI. Citations for externally created PAI or CAI sources should include “the most stable and permanent location of the data on the internet (URL), within commercial data stores, or government systematic storage” (ICS 206-01 2024). When a source changes rapidly and played a role in shaping the product’s conclusions, a record of the source must be preserved for at least one year from the date the product is issued (ICS 206-01 2024).
A link to a government statistical database that has maintained the same URL structure for years is a different citation problem than a link to a social media post that could be deleted tomorrow. The standard tells analysts to cite the most permanent available location: the original data repository rather than a third-party mirror when possible, and a stable institutional URL over an ephemeral social media link when the same information is available through both.
For OSINT practitioners, this reinforces habits that experienced collectors already follow: archive what you cite, capture metadata alongside content, and build your citation around the most durable access path you can find. A webpage archived through the Wayback Machine with a timestamped snapshot is a stronger citation than a live URL that may change or vanish. A PDF copy of a court filing stored locally with the date of access noted is more reliable than a link to a court’s electronic filing system that may reorganize its URL structure. The reader who checks the citation two years from now should be able to reach the same information the analyst used.
What This Means Outside the IC
ICS 206-01 is written for IC practitioners working within classified production systems, but the problems it solves show up everywhere. Any practitioner who works with publicly or commercially available information has to answer the same questions: What kind of information am I working with, and how does that affect what I owe the reader? How do I cite a source that sits behind a paywall? How do I document my use of AI tools so the reader can evaluate what those tools contributed? How do I handle data that’s been aggregated and repackaged by a third party? How do I preserve sources that might disappear?
Most organizations outside the IC don’t need the IC’s level of formalization, but they need answers to the same questions. The PAI/CAI/OSINT categories give you a way to think about information types that most practitioners treat as interchangeable but aren’t. The AI citation requirements give you a template for documenting AI use in finished analysis even if you don’t follow the IC’s exact format. The provenance chain requirements give you a principle for handling third-party data: tell the reader where the data actually came from, which platform served it up, and what happened to it along the way.
The 2024 update exists because analysts now routinely cite AI-generated outputs, rely on commercial platforms that sit between them and the original data, and work with sources that can disappear overnight. ICS 206-01 tells them how to document all of that so the reader can evaluate it, and these principles should apply wherever intelligence work happens.
References
Intelligence Community Standard 206-01. 2024. Citation and Reference for Publicly Available Information, Commercially Available Information, and Open Source Intelligence. Office of the Director of National Intelligence.
Intelligence Community Directive 206. 2015. Sourcing Requirements for Disseminated Analytic Products. Office of the Director of National Intelligence.
This piece was first published on our Substack.
Read the original on Substack